Final Project “ImSound”: Ding
ImSound: Record/Find your sounds in images
We run into a lot of sounds in our lives and sometimes we will naturally come up with certain color with those sounds. We may even form a memory of our city or living environment with some interesting sounds and colors. As for me, when I listen to some fast and happy tempo I could sense a color of dark red and when I run into some soft music, I may feel it is green or blue. Different people may have different feeling about different sounds. Therefore, ImSound is a devices aiming to encourage people collecting useless sounds in lives, all kinds of noise for example, convert them to certain colors based on their understanding and play the similar mixed sounds when run into a new image. The process stems from sound to image and then to sound.
For the user himself/herself, this device may help him/her convert some useless or even annoying sounds into some interesting funny sounds and find new information from it. As for others, this devices is like a business card of a user’s specific understanding about the world’s sounds and share to others.
Hardware improvement:
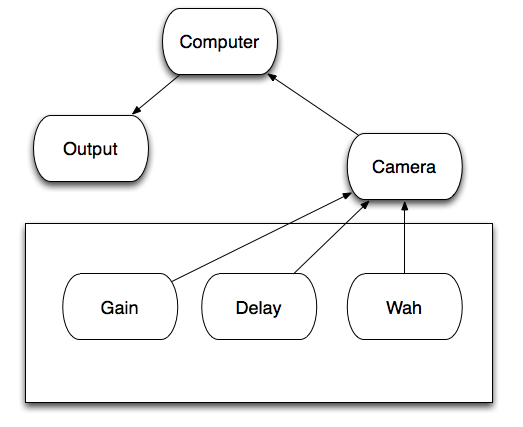
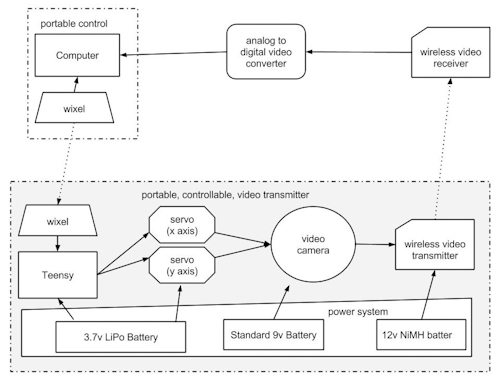
Based on last time’s feedback, people failed to get aware of the focus when capturing an image. Thus, in the final prototype, I use a magnifier attaching a camera and a mic as a portable capture device for people to focus where the sound and where they will capture an image, with a metaphor of finding sounds in our lives. Instead of several buttons to control the recording and taking image, a single push button in the handle of magnifier is used to trigger taking a photo and then automatically record a 3s sound.



Software improvement:
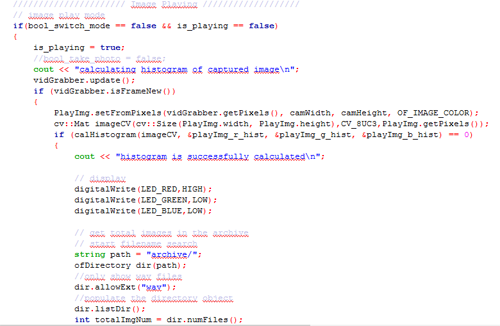
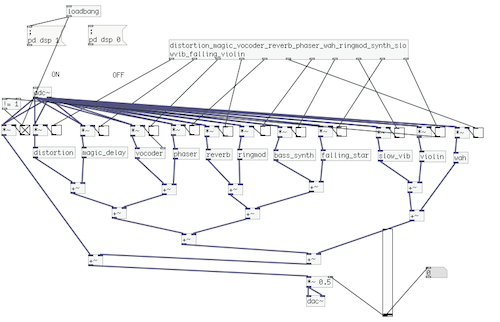
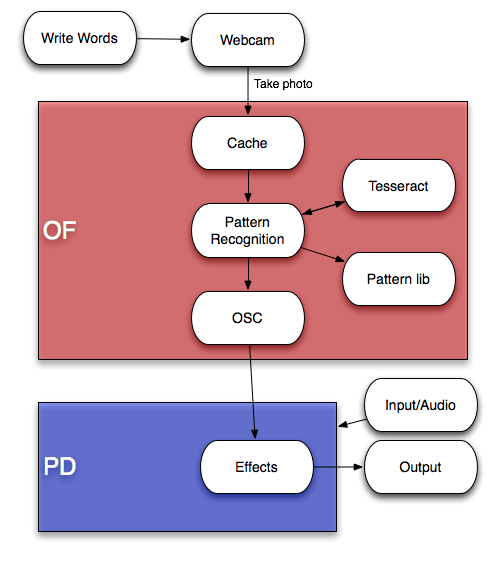
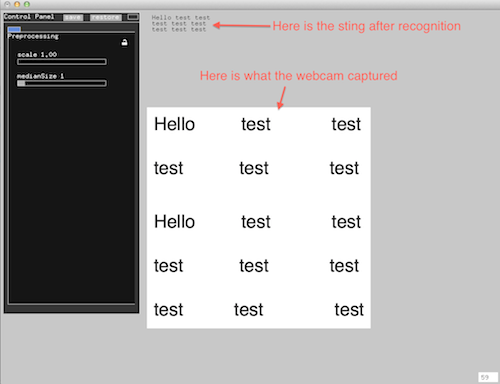
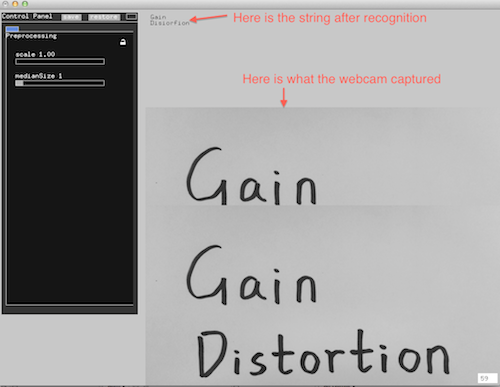
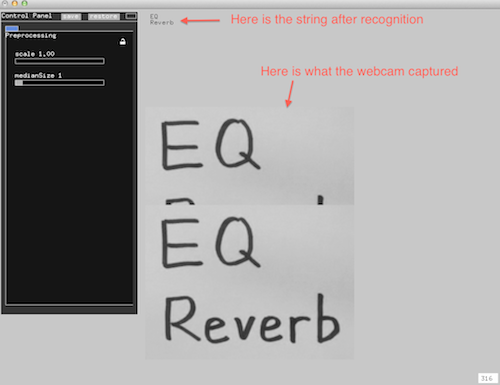
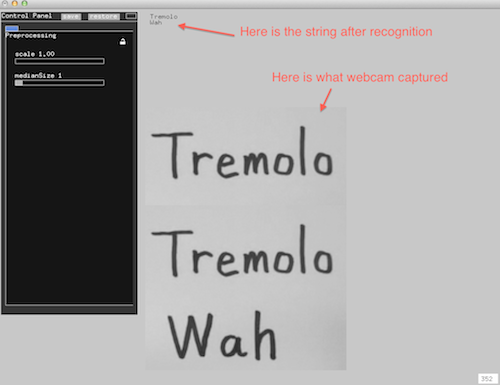
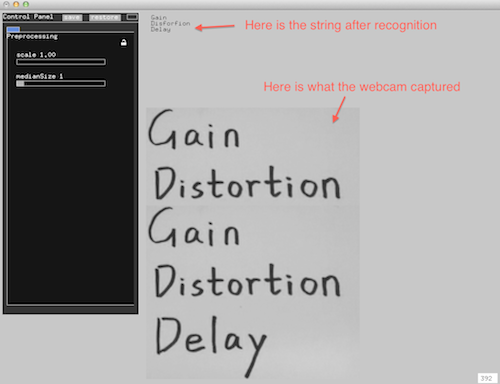
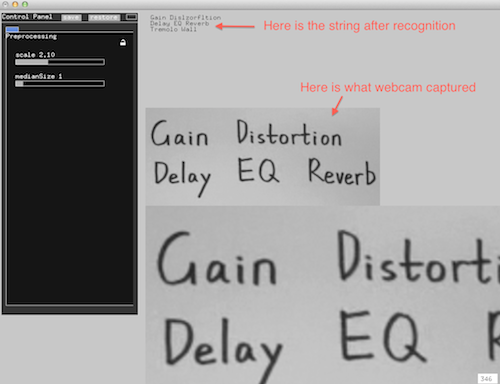
Instead of using the whole histogram of images, I converted the image from RGB to HSV and used the H value for histograms with 12 bins (variable). That is to say, the images will be divided into 12 clusters based on their major color. Each image is classified and the sound will be recorded into corresponding track contributing to the library of that color. That is to say, every color has a soundtrack which belong to this cluster. Then a granular analysis is used to divided the sound into small grains and remix them for a new sound of that class. When changing to the play mode, the H histogram is computed and the corresponding sound will be played.
I used a OF ofxMaxim with FFT processing for granular analysis, but the output sound effect is not that good. The speed of sound is changed but without much similar grains connecting together. This is a main aspect I should improve for the next step of this project.
Demo Video:
Future Plan:
1. the most important is to get more in-depth granular analysis to re-mix the sounds. My current thought is to combine the grains with their similarities among each other. The funny part is that with the growing of number of recording sounds, the output sound is dynamic changing and form some new sound.
2. Take some more actual image and sound to test the effects of whole process. Aiming to a specific type of sound may be a good choice, such as city noise.
Conclusion/Acknowledge:
Although this project is far from fully completion, I learned a lot in this process, not only the technologies such as RPI, openFrameworks and Linux; more importantly, I learned a lot about input/output design, mapping, and telling story (a point I did not do well). It teaches me to think why should we design this device and inspired me to think whom and where does a device will be used in my future projects. Thanks Ali Momeni very much for his suggestions and all the conversations during this whole process of project, and all the reviewers and classmates who help me to improve my ideas and project.